1.Google论文与开源
自1998年成立,至今Google已走过20个年头。在这20年里,Google不断地发表一些对于自己来说已经过时甚至不再使用的技术的论文,但是发表之后总会有类似系统被业界实现出来,也足以说明google的技术至少领先业界数年。在Amazon不断引领全球云计算浪潮开发出一系列面向普罗大众的云产品的同时;Google也在不断引领构建着满足互联网时代海量数据的存储计算和查询分析需求的软硬件基础设施。
本文对Google在这20年中发表的论文进行了一个简单的总结和整理,主要选择了分布式系统和并行计算领域相关的论文,其中内容涉及数据中心/计算/存储/网络/数据库/调度/大数据处理等多个方向。通过这样的一个总结,一方面可以一窥Google强大的软硬件基础设施,另一方面也可以为不同领域的开发人员提供一个学习的参考。可以通过这些文章去了解上层应用的架构设计和实现,进而可以更好的理解和服务于上层应用。同时这些系统中所采用的架构/算法/设计/权衡,本身也可以为我们的系统设计和实现提供重要的参考。
通过Google论文可以了解到系统整体的架构,通过对应开源系统可以在代码层面进行学习。具体如下图(浅蓝色部分为Google论文/黄色为开源系统):
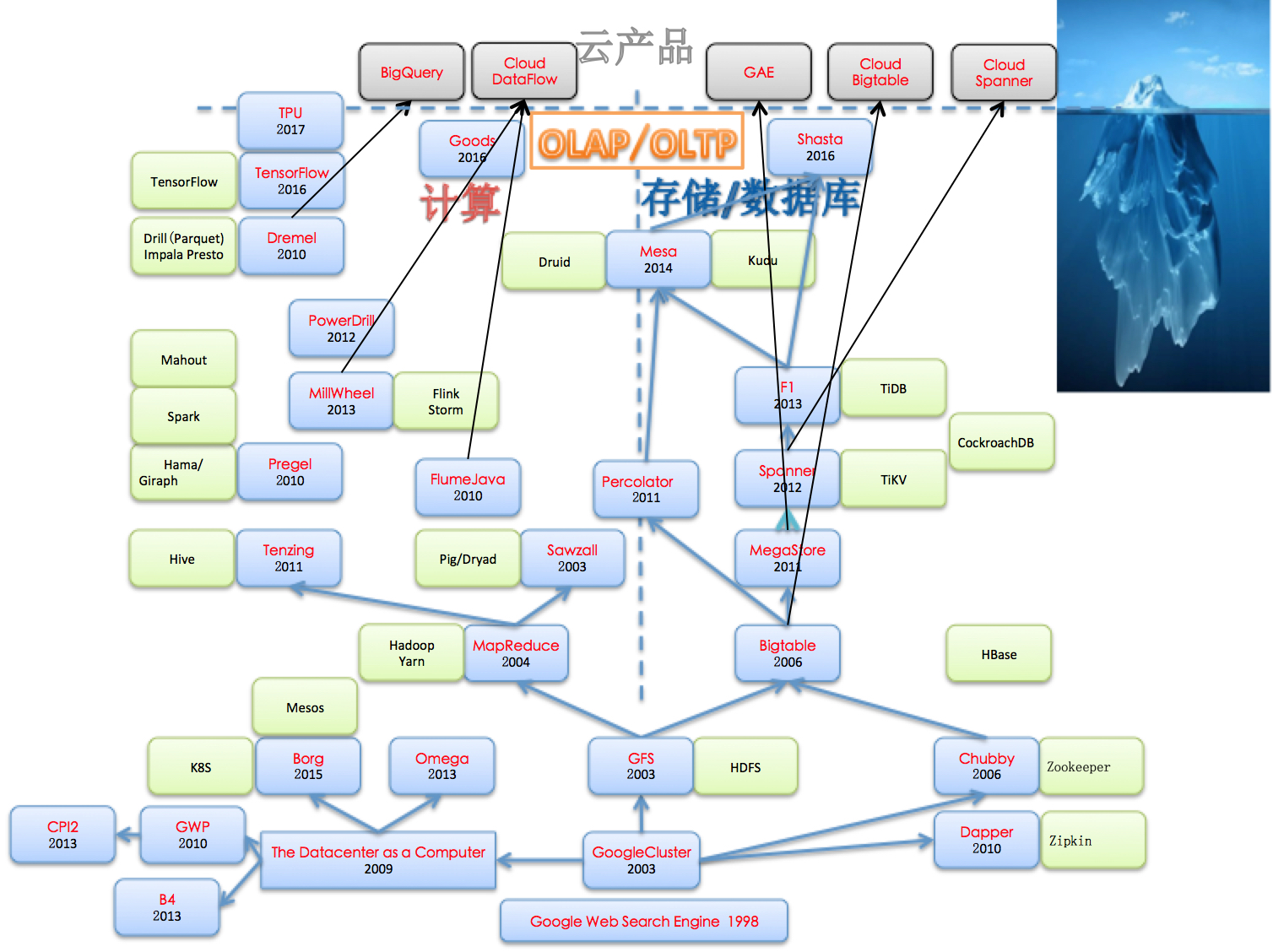
2.Google论文简介
下面来简要介绍下”那些年我们追过的Google论文”,由于篇幅有限主要讲下每篇论文的主要思路,另外可能还会介绍下论文作者及论文本身的一些八卦。深入阅读的话,可以直接根据下面的链接查看原文,另外很多文章网上已经有中文译文,也可以作为阅读参考。
2.1 起源
1.The anatomy of a large-scale hypertextual Web search engine(1998).Google创始人Sergey Brin和Larry Page于1998年发表的奠定Google搜索引擎理论基础的原始论文。在上图中我们把它放到了最底层,在这篇论文里他们描述了最初构建的Google搜索引擎基础架构,可以说所有其他文章都是以此文为起点。此文对于搜索引擎的基本架构,尤其是Google使用的PageRank算法进行了描述,可以作为了解搜索引擎的入门文章。
2.WEB SEARCH FOR A PLANET: THE GOOGLE CLUSTER ARCHITECTURE(IEEE Micro03).描述Google集群架构最早的一篇文章,同时也应该是最被忽略的一篇文章,此文不像GFS MapReduce Bigtable那几篇文章为人所熟知,但是其重要性丝毫不亚于那几篇。这篇文章体现了Google在硬件方面的一个革命性的选择:在数据中心中使用廉价的PC硬件取代高端服务器。这一选择的出发点主要基于性价比,实际的需求是源于互联网数据规模之大已经不能用传统方法解决,但是这个选择导致了上层的软件也要针对性地进行重新的设计和调整。由于硬件可靠性的降低及数量的上升,意味着要在软件层面实现可靠性,需要采用多个副本,需要更加自动化的集群管理和监控。也是从这个时候开始,Google开始着眼于自己设计服务器以及数据中心相关的其他硬件,逐步从托管数据中心向自建数据中心转变。而Google之后实现的各种分布式系统,都可以看做是基于这一硬件选择做出的软件层面的设计权衡。
再看下本文的作者:Luiz André Barroso/Jeff Dean/Urs Hölzle,除了Jeff Dean,其他两位也都是Google基础设施领域非常重要的人物。Urs Holzle是Google的第8号员工,最早的技术副总裁,一直在Google负责基础设施部门,Jeff Dean和Luiz Barroso等很多人都是他招进Google的,包括当前Google云平台的掌门人Diane Greene(VMWare联合创始人)据说也是在他的游说下才最终决定掌管GCP。Luiz Barroso跟Jeff Dean在加入Google以前都是在DEC工作,在DEC的时候他参与了多核处理器方面的工作,是Google最早的硬件工程师,在构建Google面向互联网时代的数据中心硬件基础设施中做了很多工作。到了2009年,Luiz André Barroso和Urs Hölzle写了一本书,书名就叫<<The Datacenter as a Computer>>,对这些工作(数据中心里的服务器/网络/供电/制冷/能效/成本/故障处理和修复等)做了更详细的介绍。
3.The Google File System(SOSP03).Google在分布式系统领域发表的最早的一篇论文。关于GFS相信很多人都有所了解,此处不再赘言。今天Google内部已经进化到第二代GFS:Colossus,而关于Colossus目前为止还没有相关的论文,网上只有一些零散介绍:Colossus。简要介绍下本文第一作者Sanjay Ghemawat,在加入Google之前他也是在DEC工作,主要从事Java编译器和Profiling相关工作。同时在DEC时代他与Jeff Dean就有很多合作,而他加入Google也是Jeff Dean先加入后推荐他加入的,此后的很多工作都是他和Jeff Dean一块完成的,像后来的MapReduce/BigTable/Spanner/TensorFlow,在做完Spanner之后,Jeff Dean和Sanjay开始转向构建AI领域的大规模分布式系统。2012年,Jeff Dean和Sanjay共同获得了ACM-Infosys Foundation Award。此外Google的一些开源项目像LevelDB/GPerftools/TCMalloc等,都可以看到Sanjay的身影。
4.MapReduce: Simplified Data Processing on Large Clusters(OSDI04).该文作者是Jeff Dean和Sanjay Ghemawat,受Lisp语言中的Map Reduce原语启发,在大规模分布式系统中提供类似的操作原语。在框架层面屏蔽底层分布式系统实现,让用户只需要关注如何编写自己的Mapper和Reducer实现,从而大大简化分布式编程。时至今日MapReduce已经成为大规模数据处理中广泛应用的一种编程模型,虽然之后有很多新的编程模型不断被实现出来,但是在很多场景MapReduce依然发挥着不可替代的作用。
而自2004年提出之后,中间也出现过很多关于MapReduce的争论,最著名的应该是2008年1月8号David J. DeWitt和Michael Stonebraker发表的一篇文章<< MapReduce: A major step backwards>>,该文发表后引起了广泛的争论。首先介绍下这两位都是数据库领域的著名科学家,David J. DeWitt,ACM Fellow,2008年以前一直在大学里搞研究,在并行数据库领域建树颇多,之后去了微软在威斯康辛的Jim Gray系统实验室。Michael Stonebraker(2014图灵奖得主),名头要更大一些,在1992 年提出对象关系数据库。在加州伯克利分校计算机教授达25年,在此期间他创作了Ingres, Illustra, Cohera, StreamBase Systems和Vertica等系统。其中Ingres是很多现代RDBMS的基础,比如Sybase、Microsoft SQL Server、NonStop SQL、Informix 和许多其他的系统。Stonebraker曾担任过Informix的CEO,自己还经常出来创个业,每次还都成功了。关于这个争论,Jeff Dean和Sanjay Ghemawat在2010年1月份的<<Communication of the ACM>>上发表了这篇<<MapReduce-A Flexible Data Processing Tool>>进行回应,同一期上还刊了Michael Stonebraker等人的<<MapReduce and Parallel DBMSs-Friends or Foes >>。
5.Bigtable: A Distributed Storage System for Structured Data(OSDI06).Bigtable基于GFS构建,提供了结构化数据的可扩展分布式存储。自Bigtable论文发表之后,很快开源的HBase被实现出来,此后更是与Amazon的Dynamo一块引领了NoSQL系统的潮流,之后各种NoSQL系统如雨后春笋般出现在各大互联网公司及开源领域。此外在tablet-server中采用的LSM-Tree存储结构,使得这种在1996年就被提出的模型被重新认识,并广泛应用于各种新的存储系统实现中,成为与传统关系数据库中的B树并驾齐驱的两大模型。
如果说MapReduce代表着新的分布式计算模型的开端的话,Bigtable则代表着新的分布式存储系统的开端。自此之后在分布式计算存储领域,Google不断地推陈出新,发表了很多新的计算和存储系统,如上图中所示。在继续介绍这些新的计算存储系统之前,我们回到图的底层,关注下基础设施方面的一些系统。
2.2 基础设施
6.The Chubby lock service for loosely-coupled distributed systems(OSDI06).以文件系统接口形式提供的分布式锁服务,帮助开发者简化分布式系统中的同步和协调工作,比如进行Leader选举。除此之外,这篇文章一个很大的贡献应该是将Paxos应用于工业实践,并极大地促进了Paxos的流行,从这个时候开始Paxos逐渐被更多地工业界人士所熟知并应用在自己的分布式系统中。此后Google发表的其他论文中也不止一次地提到Paxos,像MegaStore/Spanner/Mesa都有提及。此文作者Mike Burrows加入Google之前也是在DEC工作,在DEC的时候他还是AltaVista搜索引擎的主要设计者。
7.Borg(Eurosys15) Omega(Eurosys13) Kubernetes.Borg是Google内部的集群资源管理系统,大概诞生在2003-2004年,在Borg之前Google通过两个系统Babysitter和Global Work Queue来分别管理它的在线服务和离线作业,而Borg实现了两者的统一管理。直到15年Google才公布了Borg论文,在此之前对外界来说Borg一直都是很神秘的存在。而Omega主要是几个博士生在Google做的研究型项目,最终并没有实际大规模上线,其中的一些理念被应用到Borg系统中。注:Borg这个名字源自于<<星际迷航>>里的博格人,博格人生活在银河系的德尔塔象限,是半有机物半机械的生化人。博格个体的身体上装配有大量人造器官及机械,大脑为人造的处理器。博格人是严格奉行集体意识的种族,从生理上完全剥夺了个体的自由意识。博格人的社会系统由“博格集合体”组成,每个集合体中的个体成员被称为“Drone”。集合体内的博格个体通过某种复杂的子空间通信网络相互连接。在博格集合体中,博格个体没有自我意识,而是通过一个被称为博格女皇(Borg Queen)的程序对整个集合体进行控制。
在2014年中的时候,Google启动了Kubernetes(Borg的开源版本)。2015年,Kubernetes 1.0 release,同时Google与Linux基金会共同发起了CNCF。2016年,Kubernates逐渐成为容器编排管理领域的主流。提到Kubernates,需要介绍下著名的分布式系统专家Eric Brewer,伯克利教授&Google infrastructure VP,互联网服务系统早期研究者。早在1995年他就和Paul Gauthier创立了Inktomi搜索引擎(2003年被Yahoo!收购,李彦宏曾在这家公司工作),此时距离Google创立还有3年。之后在2000年的PODC上他首次提出了CAP理论,2012年又对CAP进行了回顾。2011年他加入了Google,目前在负责推动Kubernetes的发展。
8.CPI2: CPU performance isolation for shared compute clusters(Eurosys13).通过监控CPI(Cycles-Per-Instruction)指标,结合历史运行数据进行分析预测找到影响系统性能的可疑程序,限制其CPU使用或进行隔离/下线,避免影响其他关键应用。本文也从一个侧面反映出,为了实现离线在线混布Google在多方面所做的努力和探索,尤其是在资源隔离方面。具体实现中,每台机器上有一个守护进程负责采集本机上运行的各个Job的CPI数据(通过采用计数模式/采样等方法降低开销,实际CPU开销小于0.1%),然后发送到一个中央的服务器进行聚合,由于集群可能是异构的,每个Job还会根据不同的CPU类型进行单独聚合,最后把计算出来的CPI数据的平均值和标准差作为CPI spec。结合CPI历史记录建立CPI预测模型,一旦出现采样值偏离预测值的异常情况,就会记录下来,如果异常次数超过一定阈值就启动相关性分析寻找干扰源,找到之后进行相应地处理(限制批处理作业的CPU使用/调度到单独机器上等)。讲到这里,不仅让我们联想到今天大火的AIOPS概念,而很久之前Google已经在生产系统上使用类似技术。不过在论文发表时,Google只是打开了CPI2的监控功能,实际的自动化处理还未在生产系统中打开。
9.GOOGLE-WIDE PROFILING:A CONTINUOUS PROFILING INFRASTRUCTURE FOR DATA CENTERS(IEEE Micro10).Google的分布式Profiling基础设施,通过收集数据中心的机器上的各种硬件事件/内核事件/调用栈/锁竞争/堆内存分配/应用性能指标等信息,通过这些信息可以为程序性能优化/Job调度提供参考。为了降低开销,采样是在两个维度上进行,首先是在整个集群的机器集合上采样同一时刻只对很少一部分机器进行profiling,然后在每台机器上再进行基于事件的采样。底层通过OProfile采集系统硬件监控指标(比如CPU周期/L1 L2 Cache Miss/分支预测失败情况等),通过GPerfTools采集应用程序进程级的运行指标(比如堆内存分配/锁竞争/CPU开销等)。收集后的原始采样信息会保存在GFS上,但是这些信息还未与源代码关联上,而部署的binary通常都是去掉了debug和符号表信息,采用的解决方法是为每个binary还会保存一个包含debug信息的未被strip的原始binary,然后通过运行MapReduce Job完成原始采样信息与源代码的关联。为了方便用户查询,历史Profiling数据还会被加载到一个分布式数据库中。通过这些Profiling数据,除了可以帮助应用理解程序的资源消耗和性能演化历史,还可以实现数据驱动的数据中心设计/构建/运维。
10.Dapper, a Large-Scale Distributed Systems Tracing Infrastructure(Google TR10).Google的分布式Tracing基础设施。Dapper最初是为了追踪在线服务系统的请求处理过程。比如在搜索系统中,用户的一个请求在系统中会经过多个子系统的处理,而且这些处理是发生在不同机器甚至是不同集群上的,当请求处理发生异常时,需要快速发现问题,并准确定位到是哪个环节出了问题,这是非常重要的,Dapper就是为了解决这样的问题。对系统行为进行跟踪必须是持续进行的,因为异常的发生是无法预料的,而且可能是难以重现的。同时跟踪需要是无所不在,遍布各处的,否则可能会遗漏某些重要的点。基于此Dapper有如下三个最重要的设计目标:低的额外开销,对应用的透明性,可扩展。同时产生的跟踪数据需要可以被快速分析,这样可以帮助用户实时获取在线服务状态。
11.B4: Experience with a Globally-Deployed Software Defined WAN(Sigcomm13).Google在全球有几十个数据中心,这些数据中心之间通常通过2-3条专线与其他数据中心进行连接。本文描述了Google如何通过SDN/OpenFlow对数据中心间的网络进行改造,通过对跨数据中心的流量进行智能调度,最大化数据中心网络链路的利用率。Google通过强大的网络基础设施,使得它的跨越全球的数据中心就像一个局域网,从而为后续很多系统实现跨数据中心的同步复制提供了网络层面的保障。
2.3 计算分析系统
自MapReduce之后,Google又不断地开发出新的分布式计算系统,一方面是为了提供更易用的编程接口(比如新的DSL/SQL语言支持),另一方面是为了适应不同场景(图计算/流计算/即席查询/内存计算/交互式报表等)的需求。
12.Interpreting the Data: Parallel Analysis with Sawzall(Scientific Programming05).Google为了简化MapReduce程序的编写,而提出的一种新的DSL。后来Google又推出了Tenzing/Dremel等数据分析系统,到了2010年就把Sawzall给开源了,项目主页:http://code.google.com/p/szl/。虽然与Tenzing/Dremel相比, Sawzall所能做的事情还是比较有限,但是它是最早的,同时作为一种DSL毕竟还是要比直接写MapReduce job要更易用些。
本文第一作者Rob Pike,当今世界上最著名的程序员之一,<<Unix编程环境>> <<程序设计实践>>作者。70年代就加入贝尔实验室,跟随Ken Thompson&DMR(二人因为发明Unix和C语言共同获得1983年图灵奖)参与开发了Unix,后来又跟Ken一块设计了UTF-8。2002年起加入Google,之后搞了Sawzall,目前跟Ken Thompson一块在Google设计开发Go语言。
13.FlumeJava: Easy, Efficient Data-Parallel Pipelines(PLDI10).由于实际的数据处理中,通常都不是单个的MapReduce Job,而是多个MapReduce Job组成的Pipeline。为了简化Pipleline的管理和编程,提出了FlumeJava框架。由框架负责MapReduce Job的提交/中间数据管理,同时还会对执行过程进行优化,用户可以方便地对Pipeline进行开发/测试/运行。另外FlumeJava没有采用新的DSL,而是以Java类库的方式提供给用户,用户只需要使用Java语言编写即可。
14.Pregel: A System for Large-Scale Graph Processing(SIGMOD10).Google的图处理框架。Pregel这个名称是为了纪念欧拉,在他提出的格尼斯堡七桥问题中,那些桥所在的河就叫Pregel,而正是格尼斯堡七桥问题导致了图论的诞生。最初是为了解决PageRank计算问题,由于MapReduce并不适于这种场景,所以需要发展新的计算模型去完成这项计算任务,在这个过程中逐步提炼出一个通用的图计算框架,并用来解决更多的问题。核心思想源自BSP模型,这个就更早了,是在上世纪80年代由Leslie Valiant(2010年图灵奖得主)提出,之后在1990的Communications of the ACM 上,正式发表了题为A bridging model for parallel computation的文章。
15.Dremel: Interactive Analysis of Web-Scale Datasets(VLDB10).由于MapReduce的延迟太大,无法满足交互式查询的需求,Google开发了Dremel系统。Dremel主要做了三件事:将嵌套记录转换为列式存储,并提供快速的反向组装;类sql的查询语言;类搜索系统的查询执行树。通过列式存储降低io,将速度提高一个数量级,这类似于诸如Vertica这样的列存式数据库,与传统行式存储不同,它们只需要读取查询语句中真正必需的那些字段数据;通过类搜索系统的查询执行系统取代mr(MapReduce),再提高一个数量级。它类似于Hive,应该说查询层像Hive,都具有类似于SQL的查询语言,都可以用来做数据挖掘和分析;但hive是基于mr,所以实时性要差,Dremel则由于它的查询执行引擎类似于搜索服务系统,因此非常适合于交互式的数据分析方式,具有较低的延迟,但是通常数据规模要小于mr;而与传统数据库的区别是,它具有更高的可扩展性和容错性,结构相对简单,可以支持更多的底层存储方式。其中的数据转化与存储方式,巧妙地将Protobuf格式的嵌套记录转换成了列式存储,同时还能够快速的进行重组,是其比较独特的一点。
16.Tenzing A SQL Implementation On The MapReduce Framework(VLDB11).Tenzing是一个建立在MapReduce之上的用于Google数据的ad hoc分析的SQL查询引擎。Tenzing提供了一个具有如下关键特征的完整SQL实现(还具有几个扩展):异构性,高性能,可扩展性,可靠性,元数据感知,低延时,支持列式存储和结构化数据,容易扩展。Tenzing的发表算是很晚的了,与之相比Facebook在VLDB09上就发表了Hive的论文。与开源系统Hive的优势在于它跟底层所依赖的MapReduce系统都是一个公司内的产品,因此它可以对MapReduce做很多改动,以满足Tenzing某些特殊性的需求,最大化Tenzing的性能。
17.PowerDrill:Processing a Trillion Cells per Mouse Click(VLDB12).Google推出的基于内存的列存数据库,该系统在2008年就已经在Google内部上线。与Dremel相比虽然都是面向分析场景,但是PowerDrill主要面向的是少量核心数据集上的多维分析,由于数据集相对少同时分析需求多所以可以放到内存,在把数据加载到内存分析之前会进行复杂的预处理以尽量减少内存占用。而Dremel则更加适合面向大量数据集的分析,不需要把数据加载到内存。
主要采用了如下技术进行加速和内存优化:1)导入时对数据进行分区,然后查询时根据分区进行过滤尽量避免进行全量扫描 2)底层数据采用列式存储,可以跳过不需要的列 3)采用全局/chunk两级字典对列值进行编码,一方面可以加速计算(chunk级的字典可以用来进行针对用户查询的chunk过滤,编码后的value变成了更短的int类型与原始值相比可以更快速的进行相关运算),另一方面还可以达到数据压缩的目的,与通用压缩算法相比采用这种编码方式的优点是:读取时不需要进行解压这样的预处理,同时支持随机读取 4)编码后的数据进行压缩还可以达到1.4-2倍的压缩比,为了避免压缩带来的性能降低,采用了压缩与编码的混合策略,对数据进行分层,最热的数据是解压后的编码数据,然后稍冷的数据也还会进行压缩 5)对数据行根据partition key进行重排序,提高压缩比 6)查询分布式执行,对于同一个查询会分成多个子查询并发给多个机器执行,同时同一个子查询会发给两台机器同时执行,只要有一个返回即可,但是另一个最终也要执行完以进行数据预热。
18.MillWheel: Fault-Tolerant Stream Processing at Internet Scale(VLDB13).Google的流计算系统,被广泛应用于构建低延迟数据处理应用的框架。用户只需要描述好关于计算的有向图,编写每个节点的应用程序代码。系统负责管理持久化状态和连续的记录流,同时将一切置于框架提供的容错性保证之下。虽然发布的比较晚,但是其中的一些机制(比如Low Watermark)被借鉴到开源的Flink系统中。
19.Mesa: Geo-Replicated, Near Real-Time, Scalable Data Warehousing(VLDB14).Google的跨数据中心数据仓库系统,主要是为了满足广告业务的场景需求,随着广告平台的不断发展,客户对各自的广告活动的可视化提出了更高的要求。对于更具体和更细粒度的信息需求,直接导致了数据规模的急速增长。虽然Google已经把核心广告数据迁移到了Spanner+F1上,但是对于这种广告效果实时统计需求来言,由于涉及非常多的指标这些指标可能是保存在成百上千张表中,同时这些指标与用户点击日志相关通常对应着非常大的峰值访问量,超过了Spanner+F1这样的OLTP系统的处理能力。为此Google构建了Mesa从而能处理持续增长的数据量,同时它还提供了一致性和近实时查询数据的能力。具体实现方法是:将增量更新进行batch,提交者负责为增量数据分配版本号,利用Paxos对跨数据中心的版本数据库进行更新,基于MVCC机制提供一致性访问。底层通过Bigtable存储元数据,通过Colossus来存储数据文件,此外还利用MapReduce来对连续增量数据进行合并,而为Mesa提供增量更新的上游应用通常是一个流计算系统。可以看到Mesa系统本身结合了批量处理与实时计算,还要满足OLTP+OLAP的场景需求,同时采用了分层架构实现存储计算的分离。既像一个分布式数据库,又像一个大数据准实时处理系统。
20.Shasta: Interactive Reporting At Scale(SIGMOD16).Google的交互式报表系统,也主要是为了满足广告业务的场景需求,与Mesa的区别在于Shasta是构建于Mesa之上的更上层封装。主要为了解决如下挑战:1)用户查询请求的低延迟要求 2)底层事务型数据库的schema与实际展现给用户的视图不友好,报表系统的开发人员需要进行复杂的转换,一个查询视图底层可能涉及多种数据源(比如F1/Mesa/Bigtable等) 3)数据实时性需求,用户修改了广告预算后希望可以在新的报表结果中可以马上体现出来。为了解决这些问题,在F1和Mesa系统之上构建了Shasta。主要从两个层面进行解决:语言层面,在SQL之上设计了一种新的语言RVL(Relational View Language),通过该语言提供的机制(自动聚合/子句引用/视图模板/文本替换等)可以比SQL更加方便地描述用户的查询视图,RVL编译器会把RVL语句翻译成SQL,在这个过程中还会进行查询优化;系统层面,直接利用了F1的分布式查询引擎,但是进行了一些扩展比如增加单独的UDF server让UDF的执行更加安全,为了确保实时性需要直接访问F1,但是为了降低延迟在F1之上增加了一个只读的分布式Cache层。
21.Goods: Organizing Google’s Datasets(SIGMOD16).Google的元数据仓库Goods(Google DataSet Search)。Google内部积累了大量的数据集,而这些数据散落在各种不同的存储系统中(GFS/Bigtable/Spanner等)。面临的问题就是如何组织管理这些数据,使得公司内部工程师可以方便地找到他们需要的数据,实现数据价值的最大化。Google的做法很多方面都更像一个小型的搜索引擎,不过在这个系统里被索引的数据由网页变成了Google内部生产系统产生的各种数据,用户变成了内部的数据开发人员。整个做法看起来要费劲很多,很大程度上是因为内部系统众多但是没有一个统一的入口平台,只能采用更加自动化(不依赖人和其他系统)的做法:要爬取各个系统的日志,通过日志解析数据的元信息(这个过程中还是比较费劲的,比如为了确定数据的Schema,要把Google中央代码库里的所有protobuf定义拿过来试看哪个能匹配上),然后把这些信息(大小/owner/访问权限/时间戳/文件格式/上下游/依赖关系/Schema/内容摘要等)保存一个中央的数据字典中(存储在Bigtable中目前已经索引了260亿条数据集信息),提供给内部用户查询。这中间解决了如下一些问题和挑战:Schema探测/数据自动摘要/血缘分析/聚类/搜索结果ranking/过期数据管理/数据备份等。本文可以让我们一窥Google是如何管理内部数据资产的,有哪些地方可以借鉴。
2.4 存储&数据库
22.Percalator:Large-scale Incremental Processing Using Distributed Transactions and Notifications(OSDI10).基于Bigtable的增量索引更新系统,Google新一代索引系统”咖啡因“实时性提升的关键。此前Google的索引构建是基于MapReduce,全量索引更新一次可能需要几天才能完成,为了提高索引更新的实时性Google构建了增量更新系统。Bigtable只支持单行的原子更新,但是一个网页的更新通常涉及到其他多个网页(网页间存在链接关系比如更新的这个网页上就有其他网页的锚文本)的更新。为了解决这个问题,Percolator在Bigtable之上通过两阶段提交实现了跨行事务。同时网页更新后还要触发一系列的处理流程,Percolator又实现了类似于数据库里面的触发器机制,当Percolator中的某个cell数据发生变化,就触发应用开发者指定的Observer程序。此外开源分布式数据库TiDB就参考了Percalator的事务模型。
23.Megastore: Providing Scalable, Highly Available Storage for Interactive Services(CIDR11).Google在2008年的SIGMOD上就介绍了Megastore,但是直到2011年才发表完整论文。Megastore本身基于Bigtable,在保留可扩展/高性能/低延迟/高可用等优点的前提下,引入了传统关系数据库中的很多概念比如关系数据模型/事务/索引,同时基于Paxos实现了全球化同步复制,可以说是最早的分布式数据库实现了。它本身也提供了分布式事务支持,但是论文中并没有描述相关实现细节,猜测应该跟Percalator类似。虽然此后被Spanner所替代,但是它的继任者Spanner很多特性都是受它影响。
24.Spanner: Google’s Globally-Distributed Database(OSDI12).2009年Jeff Dean的一次分享(Designs, Lessons and Advice from Building Large Distributed)中首次提到Spanner,也是过了3年到了2012年才发表完整论文。做为Megastore的继任者,它主要解决了Megastore存在的几个问题:性能、查询语言支持弱、分区不灵活。另外一个重要的创新是基于原子钟和GPS硬件实现了TrueTime API,并基于这个API实现了更强的一致性保证。除此之外其他部分则与Megastore非常类似,但是在文中对其分布式事务的实现细节进行了描述。
25.F1: A Distributed SQL Database That Scales(VLDB13).基于Spanner实现的分布式SQL数据库,主要实现了一个分布式并行查询引擎,支持一致性索引和非阻塞的在线Schema变更。与Spanner配合替换掉了Google核心广告系统中的MySQL数据库。F1这个名字来自生物遗传学,代指杂交一代,表示它结合了传统关系数据库和NoSQL系统两者的特性。
2.5 AI
26.TensorFlow: A System for Large-Scale Machine Learning(OSDI16).
27.In-Datacenter Performance Analysis of a Tensor Processing Unit(SIGARCH17).Google TPU。与往常一样,在Google公布此文的时候,新一代更强大的TPU已经开发完成。由于本文更偏重硬件,具体内容没有看。但是其中的第四作者David Patterson还是值得特别来介绍一下,因为在体系结构领域的贡献(RISC、RAID、体系结构的量化研究方法),他和John Hennessy共同获得了2017年的图灵奖:相关新闻。2016年加入Google就是去做TPU的;2018年,与他共同获得图灵奖的John Hennessy(斯坦福第十任校长、MIPS公司创始人)被任命为Google母公司Alphabet的新任主席。
3.总结
在前面两节我们对过去20年Google在分布式系统领域的经典论文进行了系统地梳理和介绍,通过这个过程我们可以看到:
每当Google发表一篇相关论文,通常都会产生一个与之对应的开源系统。比如GFS/HDFS,MapReduce/Hadoop MapReduce,BigTable/HBase,Chubby/ZooKeeper,FlumeJava/Plume,Dapper/Zipkin等等。如果把数据中心看做一台计算机的话,在数据中心之上的各种分布式系统就像当年的Unix和C语言,Hadoop及各种开源系统就像当年的Linux,而开启这个时代的人们尤其是Jeff Dean/Sanjay Ghemawat就像当年的Ken Thompson/Dennis M. Ritche,Hadoop创始人Doug Cutting就像当年的Linus Torvalds。Ken Thompson/Dennis M. Ritche因为Unix和C方面的贡献获得1983年图灵奖,或许在将来的某一天Jeff Dean/Sanjay Ghemawat也能摘得桂冠。
观察上图,我们还可以看到随着时间的推进,Google自底向上地逐步构建出一个庞大的软硬件基础设施Stack,同时每个系统内部也在不断地自我进化。而不同的系统之间,可能是互补关系,可能是继承关系,可能是替换关系。通过对这个演化过程的观察,我们也总结出一些内在的趋势和规律。论文本身固然重要,但是这些趋势和规律也很有意义。
3.1 两个维度,三个层次
如题”他山之石”,人们常说不能总是低头拉车,还要注意抬头看路。那么应该如何走出去看看,看什么呢?我们可以将其划分为两个维度(时间和空间),三个层次(架构、细节和实现),如下图:
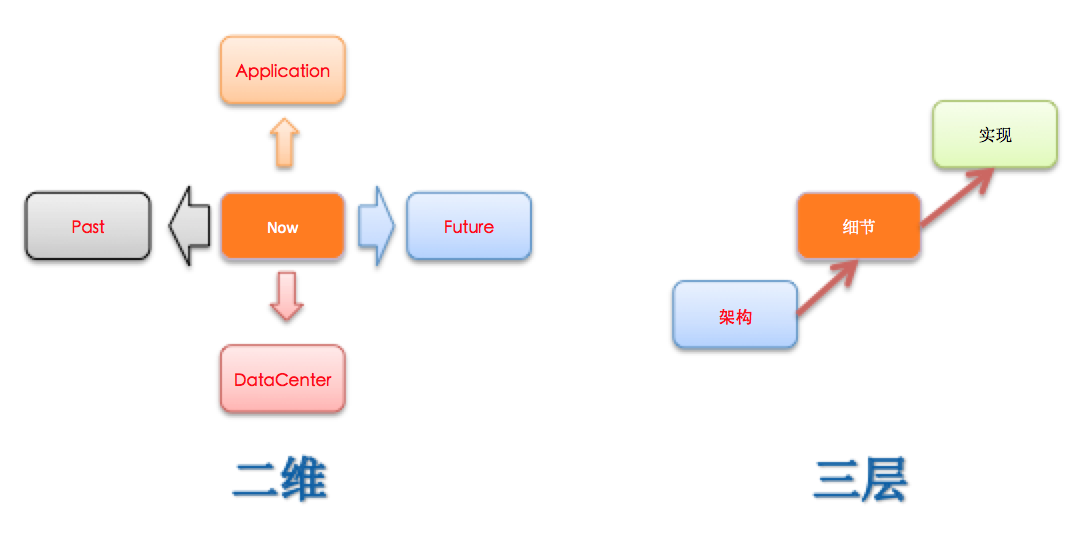
两个维度:时间维度上可以分为过去,现在和未来。Google的那些论文就属于未来,看看它们,那可能是未来要做的,当然慢慢地它们也会成为过去;经典的理论的东西,放到过去这个维度,它们是非常重要的,这决定了对系统理解的深度和高度;现在,就是正在做的或者符合目前实际环境可以直接借鉴的。人们有时候往往喜欢抓着未来,总是忽略了过去和现在,又或者是仅看着当前,忽略了未来和过去。空间维度上可以分为上层和底层,上层是指依赖于我们自己系统的那些应用,底层则指我们的系统本身底层所依赖的那些。有时候为了继续前进,需要跳出当前的框框,从多个维度上去学习,通过不断学习反过来进一步促进当前系统的演化。
三个层次:如果要了解其他系统,可以从三个层次去学习,先大概了解架构,然后深入到一些具体的细节问题,最后如果有时间还可以继续深入到代码级别。结合本文的第一张图来说就是:可以通过Google论文了解整体架构,然后通过开源系统相关wiki或文档可以了解到更细节的一些东西,最后结合开源系统还可以看到实际的代码实现。
3.2 合久必分,分久必合
天下大事,合久必分 分久必合
–三国演义
3.2.1 分
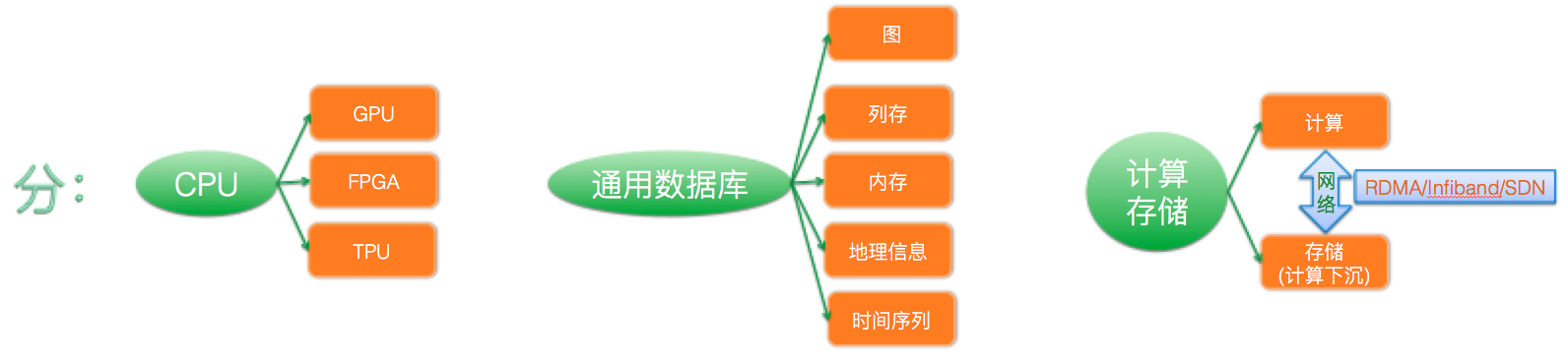
实例:
1.越来越多的计算被Offload到非CPU的计算单元:Google TPU
2.“One Size Fits All”: An Idea Whose Time Has Come and Gone:各种新的计算模型如Pregel MillWheel Dremel PowerDrill Mesa
3.计算存储分离:Mesa CFS+Spanner+F1
3.2.2 合
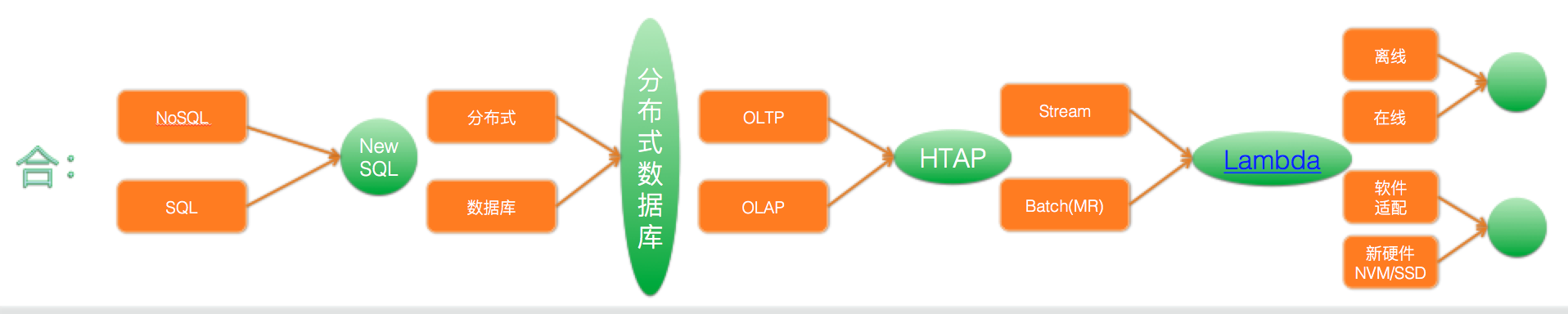
实例:
1.分布式数据库:从MegaStore开始到后来的Spanner F1,不断弥补着NoSQL的不足。同时Spanner自身仍在不断演化,开始具备更加丰富的SQL和OLAP支持。
2.流处理和批处理的统一:Cloud DataFlow完成了编程接口层面的统一,而Mesa则解决了数据层面的结合。
3.在线离线混部:Borg。
4.软硬件结合:整个基础设施,就是在解决一个软件(分布式系统)如何适配新硬件(面向互联网设计的数据中心)的问题。通过上层分布式系统屏蔽底层数据中心细节,实现”Datacenter As a Computer“。
3.3 理论与实践相结合
3.3.1 ”新瓶装旧酒“
纵观过去的20年,我们可以看到如果单纯从理论上看,Google的这些论文并没有提出新理论。它们所依赖的那些基础理论(主要来自分布式系统和关系数据库领域),基本上都是上个世纪70/80年代就已经提出的。而Google的系统只是把这些经典理论结合自己的业务场景(互联网搜索和广告),进行了实践并发扬广大使之成为业界潮流。看起来虽然是”新瓶装旧酒”,但是却不能小觑这一点,因为旧酒在新瓶里可能会产生新的化学反应,进而创造出新的完全不同的“酒”。如果忽略了它,当新”酒“成为新浪潮之时,就再也无法站立在浪潮之巅。
3.3.2 两个阶段
如果从理论与实践的这个角度来看,我们可以把过去的20年分成两个阶段:前十年主要解决的是可扩展性问题,理论主要源自分布式系统领域;后十年在解决了可扩展问题后,开始考虑易用性问题,提供更加方便的编程接口和一致性模型,这个阶段更多地是借鉴传统关系数据库领域的一些做法。再回到当下,从AI的再度流行中我们依然可以看到其所依赖的理论基础,依然是在上个世纪就已经提出的,而今天在互联网时代大规模的数据和计算能力这个背景下,重新焕发了生命。在解决完可扩展易用性问题后,使得可以对大规模数据进行方便地存储计算和查询之后,下一个十年人们开始关注如何进一步挖掘数据,如何借助这些数据去完成以前未完成的构想,这个过程中仍在不断学习应用前人的经典理论。
3.3.3 实践联系理论
从另一个方面来说,如果要真正理解这些论文,除了论文本身内容之外,也还需要去了解传统的分布式系统和关系数据库理论。比如Spanner那篇论文,如果只看论文本身,没有关系数据库和分布式系统理论基础的话估计很难看懂。有时候可能还需要多看看论文的参考文献,之后再看才会理解一些。很多研究领域的大牛们,经常会调侃做工程的家伙们,他们说”这些家伙看着就像生活在5,60年代的老家伙“,为什么呢,因为这些家伙们总是用一些很丑陋的方法去解决一个科学家们早在几十年前就给出了完美解决方案的问题,但是这些家伙看起来对此一无所知。当然了,做工程的也会挖苦下那些研究家们老是指指点点,从来不肯俯下身子来解决实际问题。但是实际上,如果你是做工程的,那就应该多看看研究家们的成果,其实很多问题的确是人家n多年前就已经提出并很好解决了的。如果是做研究的,那就多接触下工程实践,理解下现实需求,弥补下理论与实践的差距。
3.3.4 分布式理论实践
具体到分布式系统领域,我们可以发现正是通过与实践相结合,理论才逐渐赢得科学界和工业界的重视。在此之前,分布式理论研究一直处于非常尴尬的状态,与实践的隔阂尤其严重,很多研究工作局限在研究领域,严重脱离现实世界。关于这一点从图灵奖的颁发上可以看出来,自1966年图灵奖首次颁发以来,直到2013年Lamport获奖之前,可以说还没有一个人因为在分布式系统领域的贡献而获得图灵奖。虽然有些获奖者的研究领域也涉及到分布式系统,但是他们获奖更多是因为在其他领域的贡献。而反观程序设计语言/算法/关系数据库等领域均有多人获奖,同时这些领域的研究成果早已被广泛应用在工业界,通过实践证明了其价值。可以说正是因为互联网的兴起,在Google等公司的分布式系统实践下,分布式理论逐渐被广泛应用到各个实际系统中,这也是 Lamport能够获得图灵奖的重要原因。
4.云计算的起源与发展
本节我们将跳出Google论文的范畴,以更广泛的视角看一下今天的云计算。下面更多的是描述一些历史,进行一些”考古”,希望这个过程可以带来更多的启发和思考。
4.1 从Google论文说起
4.1.1 “冰山一角”
首先还是回到第一张图,我们把图缩小一下,并重点关注图的顶部。
可以看到,在Google强大的软硬件基础设施之上,在其云平台上暴露给外部用户使用的则寥寥无几。这个场景就像我们看到了一座冰山,露在水面上的只有那一角。即便是已经开放给外部用户的Cloud Bigtable是2015年才发布的,此时距离Bigtable论文发表已经过了快10年。Cloud Spanner是2017年,也已经是论文发表5年之后。虽然在2008年就推出了GAE,但是也一直不温不火。
将Google的这些系统与AWS的各种云产品对比一下,可以发现两者的出发点类似都是为了实现”Datacenter As a Computer“,但是目标用户不同。Google这些系统面向的是内部的搜索广告业务,而AWS则致力于让外部客户也能实现”Datacenter As a Computer“。就好比一个是面向大企业客户的国有大银行,一个是面向小微客户的普惠金融。从技术->产品->商品->服务的角度来看,Google在技术上做到了独步天下,但是要提供给外部客户后面的短板仍然需要补足。
早在2011年,Google员工Amazon前员工Steve Yegge在G+上发表了一篇文章对Google和Amazon进行了有趣的对比:Stevey’s Google Platforms Rant ,中文版。其中非常重要的一点就是Amazon对于服务及服务化的重视。
2015年Sundar Pichai成为Google新任CEO。进行了一系列调整,找来了VMware的联合创始人Diane Greene领导谷歌的企业及云业务,相关新闻:谷歌公有云GCP轰隆崛起?,可以看到Google正在做出很多改变,开始将云计算作为公司重要战略。同时开源了很多技术如Kubernetes和TensorFlow,试图通过容器、CloudNative和AI等新兴领域实现弯道超车。
4.1.2 为啥要发论文
还有一个有趣的对比,可以看到在过去20年Google发表了非常多的论文来介绍它的内部系统,但是反观Amazon,对于它的云产品内部实现可以说介绍的非常少,相关论文只有寥寥几篇。
对于Google来说,发表论文主要是为了增加个人和公司的业界影响力,便于赢得声誉吸引人才。当然Google内部同样有非常严格的保密机制,禁止员工向外界透露内部系统信息,除非获得了授权。通过前面的一些论文也可以看到,从系统做出来上线算,真正论文发表通常是5年之后的事情了,而发表的时候内部已经有下一代系统了。按照中国古话说”富贵不还乡,如锦衣夜行“,内部再牛逼别人看不到就没有存在感。
反观Amazon,则没有这个苦恼,因为它云平台上的所有系统都是对外开放的,外面的人可以切实地感受到它的存在,大部分情况下都不需要通过论文来提升存在感。
4.2 ”5朵云“的起源
IBM的CEO Thomas J. Watson在1943年说过这样一段话:”I think there is a world market for maybe five computers,” 后来在Cloud Computing概念提出后,逐步演变成5朵云的说法。
4.3 AWS
关于售卖计算能力给外部客户的想法最早源自2003年Benjamin Black和Chris Pinkham写的一篇报告中,这个想法引起了Jeff Bezos的兴趣。之后2004年就开干了,当时大家一致觉得Pinkham最适合去干这件事,但是他那个时候正想着回到他的家乡南非,于是Amazon就让他在南非开了新的办公室,在那里他们创建了EC2团队并开发出了EC2。Benjamin Black 在一篇文章(EC2 Origins)中介绍了这段有趣的历史。
2006年AWS正式上线了EC2和S3,自此拉开了云计算的序幕。其后续整个发展的详细历程可以参考:Timeline of Amazon Web Services。
此外还有一个比较有意思的问题:为什么 AWS 云计算服务是亚马逊先做出来,而不是 Google ?其中有偶然也有必然,简要总结一下就是”天时、地利、人和“。
参考文献
https://www.gcppodcast.com/post/episode-46-borg-and-k8s-with-john-wilkes/
https://blog.risingstack.com/the-history-of-kubernetes/
http://www.wired. com/2015/09/google-2-billion-lines-codeand-one-place/
https://en.wikipedia.org/wiki/Eric_Brewer_(scientist)
如何看待谷歌工程师透露谷歌有20亿行代码,相当于写40遍Windows?
Return of the Borg: How Twitter Rebuilt Google’s Secret Weapon
http://www.infoq.com/cn/news/2014/08/google-data-warehouse-mesa