1. cpuprofile
1.1. 原理
1.1.1. 定时器与stack追踪
Cpu-profile所依赖的重要基础有两个。
int setitimer(int which, const struct itimerval *value, struct itimerval *ovalue);
which为定时器类型,setitimer支持3种类型的定时器:
ITIMER_REAL: 以系统真实的时间来计算,它送出SIGALRM信号。
ITIMER_VIRTUAL: -以该进程在用户态下花费的时间来计算,它送出SIGVTALRM信号。
ITIMER_PROF: 以该进程在用户态下和内核态下所费的时间来计算,它送出SIGPROF信号。
setitimer()第一个参数which指定定时器类型(上面三种之一);第二个参数是结构itimerval的一个实例;第三个参数可不做处理。
setitimer()调用成功返回0,否则返回-1。
struct itimerval {
struct timeval it_interval;
struct timeval it_value;
};
struct timeval {
long tv_sec;
long tv_usec;
};
1.1.2. cpuprofile数据文件格式
http://gperftools.googlecode.com/svn/trunk/doc/cpuprofile-fileformat.html
profile文件分为两部分:二进制区域和文本区域。这里我们主要了解下二进制部分,因为这部分对理解profile原理非常有帮助。二进制区域分为三部分:header,profile records和trailer。
Header部分包含了采样时间间隔,文件格式版本信息等meta信息。
每条profile record格式如下:
|
slot |
data |
|
0 |
sample count, must be >= 1 |
|
1 |
number of call chain PCs (num_pcs), must be >= 1 |
|
2 .. (num_pcs + 1) |
call chain PCs, most-recently-called function first. |
比如如下这样一条记录:
|
5 |
3 |
0xa0000 |
0xc0000 |
0xe0000 |
5代表PC 0xa0000被采样到了5次。3表示函数链长度为3。0xa0000的调用者是0xc0000的函数,而0xc0000的调用者则是0xe0000。profiler 可能会输出具有相同调用链的多条记录。对于这种情况来说,分析工具负责将这些具有相同调用链的记录累加起来。
Trailer部分是二进制区域的结束标志。由三个整数组成,(0,1,0),它实际上等价于采样值为0,调用链中只有一个地址为0的函数的profile record。正常情况下,是不存在这样的一条记录,因此可以用来作为结束标志。
1.1.3. LD_PRELOAD
1.1.4. pprof
pprof是用来对profile过程中产生的profile结果文件进行分析的,以更友好的、易于人理解的方式展现出来,该程序实际上是个perl脚本。原始的profile文件上是由一系列的:<count> <stack trace>值对组成的。pprof的作用就是对它们进行解析,转化成可以被人们理解的输出。
主要利用了如下一些系统工具,分析生成的profile文件和二进制可执行文件:
objdump,nm,addr2line,c++filt
简单分析下这些工具的用法,主要是有时候我们可能需要手动完成一些类似工作。
1.2. 安装
在如下地址下载源码编译:
http://code.google.com/p/gperftools/downloads/list
64位操作系统需要安装libunwind,官方推荐版本是libunwind-0.99-beta:
http://download.savannah.gnu.org/releases/libunwind/
目前验证过2.4版本的可以正常编译使用。
需要注意一点,在linux下,如果直接./configure,那么make时会报出编译错误:error Cannot calculate stack trace: will need to write for your environment。解决方法如上所示,在configure时加入选项–enable-frame-pointers。
为确保pprof可以生成图片,还需要安装graphviz
wget http://www.graphviz.org/pub/graphviz/stable/SOURCES/graphviz-2.32.0.tar.gz
make时报错如下:
/usr/bin/ld: cannot find -lpython2.5
解决方法:
find / -name “*python2.5*”
sudo ln -s /usr/ali/lib/libpython2.5.so /usr/lib/libpython2.5.so
make
1.3. 使用
要进行cpuprofile,需要三步:
1. 链接库libprofiler.so到应用程序,有两种方式,一是可以在链接时时直接加上该库,一种是可以在运行时设置env LD_PRELOAD=”/usr/lib/libprofiler.so”。这一步骤实际上只是完成了代码插入,并未打开profile,因此开发过程中可以始终-lprofiler。但是由于任何用户都可以通过设置环境变量,触发profile过程,因此并不推荐在产品上线时保持这样。
2. 运行程序,需设置环境变量CPUPROFILE:env CPUPROFILE=binnary.prof ./binary
3. 利用pprof分析profile输出文件
只有linux2.6及以上版本下, profiling才可以在多线程环境下正确进行。Linux2.4下,由于内核在itimers和theads方面的bug,只能对主线程进行profiling。Profiling还可以跟踪子进程,每个子进程将会生成一个以它自己的进程号标示的profile文件。 由于安全方面的考虑,cpuprofile不会为那些调用了setuid的程序生成profile文件,因此对于它们来说是不可用的。
1.3.1. 基础
命令
export LD_PRELOAD=/usr/local/lib/libprofiler.so
env CPUPROFILE=sliding.prof ./groupby_sliding_performance_test 15 1000
pprof –text groupby_sliding_performance_test sliding.prof >prof.text
pprof –ps groupby_sliding_performance_test sliding.prof >prof.ps
ps格式可以通过如下网站转换为pdf格式:
http://www.ps2pdf.com/convert.htm
输出结果
文本输出结果,由6列组成,每列代表的含义如下:
|
列号 |
说明 |
|
1 |
分析样本数量(不包含其他函数调用) |
|
2 |
分析样本百分比(不包含其他函数调用) |
|
3 |
目前为止的分析样本百分比(不包含其他函数调用) |
|
4 |
分析样本数量(包含其他函数调用) |
|
5 |
分析样本百分比(包含其他函数调用) |
|
6 |
函数名 |
Total: 2525 samples
298 11.8% 11.8% 345 13.7% runtime.mapaccess1_fast64
268 10.6% 22.4% 2124 84.1% main.FindLoops
251 9.9% 32.4% 451 17.9% scanblock
178 7.0% 39.4% 351 13.9% hash_insert
131 5.2% 44.6% 158 6.3% sweepspan
119 4.7% 49.3% 350 13.9% main.DFS
96 3.8% 53.1% 98 3.9% flushptrbuf
95 3.8% 56.9% 95 3.8% runtime.aeshash64
95 3.8% 60.6% 101 4.0% runtime.settype_flush
88 3.5% 64.1% 988 39.1% runtime.mallocgc
通过上面输出结果可以看到各个函数的开销,但是这个信息还是很简略的。如果要进行更详细有效的分析,通常还是要依赖于具有call graph信息的图形输出结果。
图形输出结果由节点、有向边和meta信息组成。Meta信息如下:
/tmp/profiler2_unittest
Total samples: 202
Focusing on: 202
Dropped nodes with <= 1 abs(samples)
Dropped edges with <= 0 samples
每个节点代表一个函数,节点数据格式如下:
|
Class Name Method Name local (percentage) of cumulative (percentage) |
local时间是函数直接执行的指令所消耗的CPU时间(包括内联函数);性能分析通过抽样方法完成,默认是1秒100个样本(可以用环境变量CPUPROFILE_FREQUENCY来控制,默认100),一个样本是10毫秒,即时间单位是10毫秒。cumulative时间是local时间与其他函数调用的总和。如果cumulative时间与local时间相同,则不打印cumulative时间项。
有向边,调用者指向被调用者,有向边上的数字表示该函数调用在采样中出现的次数。如果某个函数调用在一个采样单元中出现多次,比如递归函数调用,每次调用都会体现在边的权重上。所以有向边上的权重代表的是函数调用在采样中出现的次数,对于普通函数来说输出边权重加上函数自身权重等于cumulative值,但是是对于递归调用来说,它与节点方框内的数字差异甚大。如下图所示,main.DFS指向自身的那条边权重是69206,很明显远远大于total sample的值。这也说明了一次采样可能出现多个函数调用,因为一个采样对应的是一个函数调用栈。反过来,我们也可以根据这个信息,得到一些关于递归函数调用栈深度的统计信息。
另外图形输出结果中,为方便查看,会对节点数目及输出边数进行限制,过滤某些过低的采样值。因此,实际图形中并不保证输出权重+函数本地权重=函数总权重,两者可能存在细微差别。用户可以通过–nodecount,–nodefraction,–edgefraction进行控制。
如果编译的时候加上-O2 优化,可能会发现生成的调用关系图和实际代码路径有点差别,这是由于图基于优化后代码运行时采样生成的。
另外,如果程序函数较多,而是想关注某个函数的调用关系,可以在执行pprof时加上–focus 参数,比如,如果只想关注和vsnprintf有关系的调用关系,可以加上–focus=vsnprintf,这样生成的图会简单很多。同样,如果不想关注某个函数,可以加上–ignore参数,比如–ignore=vsnprintf。
1.3.2. 进阶
源码对照分析
通常只需要上面的这些步骤就可以分析出程序的性能瓶颈了。但是有时候我们可能希望可以进行更细致的分析。比如想知道每行代码的开销,即我们可能想不仅仅是关注于函数级别的性能分析,还想进一步的深入到函数内部。
pprof实际上是支持这个粒度的分析的。比如,–line可以输出以行为粒度的统计结果,但是它还是无法显示出采样值与源代码行的具体对应关系。实际上我们可以通过两种方式获取这些信息。
一是pprof –list=<regexp>,另–disasm=<regexp>还可以看到汇编级的信息
二是进入交互式执行模式:
$pprof groupby_sliding_performance_test sliding.prof
(pprof) list main
Total: 2052 samples
no filename found in __libc_start_main<00000032f201d8a0>
ROUTINE ====================== main in /…test.cpp
0 2029 Total samples (flat / cumulative)
. . 193: cout << “groupby_sliding_performance_….
. . 194: cout << “example:” << endl;
. . 195: cout << “./groupby_sliding_performance_……;
. . 196: }
. . 197:
—
. . 198: int main(int argc, char* argv[])
. . 199: {
. . 200: TestSlidingGroupByPerformance T;
. . 201: if (argc != 3)
. . 202: {
. . 203: PrintHelp();
. . 204: exit(1);
. . 205: }
. 2029 206: T.TestGroupBy(….);
. . 207: return 0;
. . 208: }
—
局部profiling
如果只想对部分程序代码进行profing,可以通过在应用程序中调用ProfilerStart()和ProfilerStop()。更多内容可以参考<gperftools/profiler.h>。
另外有时由于程序运行时间很长,我们可能并不想对整个程序运行过程进行profiling,而只是想对其中某个运行片段进行。可以通过在运行时,设置CPUPROFILESIGNAL变量。具体过程如下:
% env CPUPROFILE=chrome.prof CPUPROFILESIGNAL=12 /bin/chrome &
% killall -12 chrome #开始进行profiling
% killall -12 chrome #停止进行profiling
Callgrind分析
% pprof –callgrind /bin/ls ls.prof > ls.callgrind
% kcachegrind ls.callgrind
附加说明
1. 如果程序异常退出,生成的profile文件可能是不完整的,甚至是空的
2. 图形输出结果中,可能有些区域是不联通的,原因就是因为上面的边过滤策略,导致某些权重过低的边会被抛弃
3. 如果程序链接到的某个库没有足够的符号信息,那么与该库相关的采样将会被算到程序中位于该库代码之前的最后那个符号上,这样会导致该符号相关的采样值会被人为地增加
4. 如果程序进行了fork调用,那么产生的子进程也将会被profile,同时会继承相同的CPUPROFILE设置,同时为区分不同的进程,进程id会被添加到profile文件名中
5. 执行pprof时,有时候比较耗时,需要耐心等待。ps aux|grep pprof可以看到如下一行:
1.4. 扩展阅读
http://blog.golang.org/profiling-go-programs
http://gperftools.googlecode.com/svn/trunk/doc/cpuprofile.html
Google CPU Profiler Binary Data File Format
How To Build a User-Level CPU Profiler
Continuous Profiling: Where Have All the Cycles Gone?
ProfileMe: Hardware Support for Instruction-Level Profiling on Out-of-Order Processors
2. heapprofiler
2.1. 原理
2.2. 使用
通过内存profiling,可以解决下述三类问题:
1. 获取任意时刻程序堆中的内容
2. 定位内存泄露,主要是通过比较前后两个profile文件
3. 定位那些进行大量内存申请的地方
HEAP_PROFILE_MMAP :
pprof –ignore=’DoAllocWithArena|SbrkSysAllocator::Alloc|MmapSysAllocator::Alloc
HEAP_PROFILE_ONLY_MMAP
3. heapchecker
3.1. 原理
当一个HeapLeakChecker对象被创建时,它会首先将当前内存使用状况dump为一个文件<prefix>.<name>-beg.heap,保存到一个临时目录下。在NoLeaks()被调用时,它会再dump出另一个名为<prefix>.<name>-end.heap的文件(prefix通常是运行时动态确定的,name则通常是argv[0]的值)。然后,它会对这个两个文件进行比较分析。如果第二个文件比第一个文件包含的内存多,NoLeaks()就会返回false,表示有内存泄露。
“活动对象”检测:在程序执行的任意时刻,所有可访问的内存都被认为是活动的对象。这包括所有的全局变量以及全局指针变量指向的内存,所有从当前stack frame及CPU寄存器可达的所有内存,还包括线程本地存储、thread heaps、以及从线程本地存储、thread heaps可达的内存空间。对于除“draconian”之外的所有模式来说,活动对象都不会被视为是内存泄露。
3.2. 使用
env LD_PRELOAD=”/usr/local/lib/libtcmalloc.so”
env HEAPCHECK=normal ./groupby_sliding_performance_test 15 100
运行完后发现输出如下内容:
Have memory regions w/o callers: might report false leaks
Leak check _main_ detected leaks of 1514748 bytes in 673 objects
The 20 largest leaks:
*** WARNING: Cannot convert addresses to symbols in output below.
*** Reason: Cannot find ‘pprof’ (is PPROF_PATH set correctly?)
*** If you cannot fix this, try running pprof directly.
Leak of 827392 bytes in 202 objects allocated from:
@ 2acd5c0198f1
@ 2acd5c019bb1
@ 2acd5c01b06b
@ 2acd5c01b12e
@ 2acd5bfb9de8
上面的数据结果只有地址,没有对应的代码位置。仔细观察这个输出,它已经提示出了可能的问题“Reason: Cannot find ‘pprof’ (is PPROF_PATH set correctly?)”。
echo $PPROF_PATH,发现的确为空值,设置一下
export PPROF_PATH=/usr/local/bin/pprof,再次运行发现可以正常显示泄露的代码位置了。
WARNING: Perftools heap leak checker is active — Performance may suffer
Have memory regions w/o callers: might report false leaks
Leak check _main_ detected leaks of 66448 bytes in 79 objects
The 20 largest leaks:
Using local file ./groupby_sliding_performance_test.
Leak of 8192 bytes in 1 objects allocated from:
@ 2acb2b29ae89 __gnu_cxx::new_allocator::allocate
@ 2acb2b29aeb1 std::_Vector_base::_M_allocate
@ 2acb2b2c17e9 std::vector::_M_allocate_and_copy
@ 2acb2b2c1897 std::vector::reserve
@ 2acb2b2c7516 apsara::stream::DumpableVector::DumpableVector
@ 2acb2b2cbcfe apsara::stream::StringContainerWithDel::StringContainerWithDel
@ 2acb2b2cbe43 apsara::stream::DumpableRecordVector::DumpableRecordVector
@ 2acb2fa3374e apsara::stream::GroupBy::GroupBy
@ 4418a7 TestSlidingGroupByPerformance::CtorIdentifyColInfo
@ 441b07 TestSlidingGroupByPerformanc
如果用户不想修改自己的代码,通过上面的方式就可以进行检查。如果用户希望可以只针对特定的某段代码进行检查,则可以通过在自己的代码中这样调用:
HeapLeakChecker heap_checker(“test_foo”);
{
code that exercises some foo functionality;
this code should not leak memory;
}
if (!heap_checker.NoLeaks()) assert(NULL == “heap memory leak”);
然后在运行时令HEAPCHECK=local即可。
有时候我们可能不只想知道发生泄漏的代码位置,还想知道泄漏的对象的内存地址。因为由同一行代码申请出的内存并不一定是全部都会泄漏的,我们希望可以结合程序日志,更进一步的定位出发生泄漏的具体条件。如果需要打印出现内存泄露的对象的实际地址,需要设置如下环境变量:
export HEAP_CHECK_IDENTIFY_LEAKS=1
在程序运行完的命令行输出的最后,还可以看到如下提示::
1970-01-01 09:00:00pprof ./groupby_sliding_performance_test “/tmp/groupby_sliding_performance_test.4970._main_-end.heap” –inuse_objects –lines –heapcheck –edgefraction=1e-10 –nodefraction=1e-10 –gv
1970-01-01 09:00:00If you are still puzzled about why the leaks are there, try rerunning this program with HEAP_CHECK_TEST_POINTER_ALIGNMENT=1 and/or with HEAP_CHECK_MAX_POINTER_OFFSET=-1
上面的提示告诉我们,可以使用pprof查看更详细信息,以定位泄露的代码位置。执行上述pprof命令后,我们可以看到内存泄露在call graph上的相关信息,这些信息对于快速定位内存泄露十分有帮助。如下图所示:
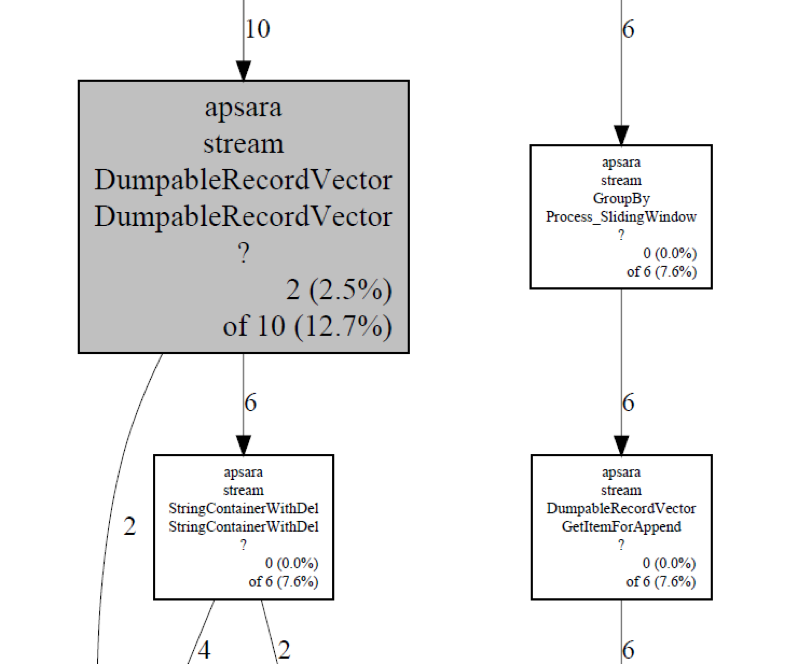
需要注意的是图中有白色方框和阴影方框,阴影方框代表就是该函数实际发生了泄露,也就是说从该函数new(malloc, allocate)出来了一些对象,但是这些对象最后未释放。因此需要仔细检查下阴影函数中的new等内存相关操作,是否具有与之相应的释放动作。
同样的,对于heap check来说,我们也可以通过–list选项或者进入交互模式,直接找到发生泄漏的那行代码及泄漏的对象数目。这种方式又比图形输出结果更近一步,直接就定位到了发生泄漏的代码行。
4. Go Profile
4.1. Cpu profile
4.1.1. 修改Code加入profile代码
flagCpuprofile := “cpuprofile.” + strconv.Itoa(i)
f, err := os.Create(flagCpuprofile)
if err != nil {
logger.Fatal(err)
return
}
pprof.StartCPUProfile(f)
CodeXXXX
pprof.StopCPUProfile()
4.1.2. 运行程序获取cpuprofile数据
之后会在程序运行路径上产生profile数据文件,cpuprofile.i将该文件拷贝到可以执行go的机器上。
然后执行如下命令:
go tool pprof –svg core_dump_manager cpuprofile.44 >heap.svg
如果不支持产生svg格式文件,可能需要安装:sudo yum install graphviz
读取svg文件:
可以将该svg格式文件发送到windows,然后通过ie浏览器读取