-
-
-
-
Jepsen测试
2020年12月19日 阅读(1,593)在线性一致性理论中我们已经介绍了Jepsen测试的理论基础。通过本文我们来看下怎么编写运行一个简单的Jepsen测试。
1.Clojure语言介绍及入门
Jepsen本身基于Clojure开发,如果想要了解Jepsen测试框架的内部实现以及其他一些开源项目的Jespen测试代码,需要能够看懂Clojure。首先我们来介绍下Clojure,Clojure是一种函数式编程语言,本身运行基于jvm,跟java可以进行很好的交互,关于Clojure的更多优点可以参考此文。Clojure这个单词,C L J分别用了代表C Lisp Java,同时又跟Closure的拼写近似。除了Jepsen之外,另一个比较有名的采用了Clojure的开源系统是Storm,这里有一个Storm采用Clojure的原因介绍。
Jepsen的作者Aphyr也写过一篇关于Clojure入门相关的文章。
下面推荐几篇关于Clojure入门的文章:
clojure-by-example 结合Clojure解释器实际运行试试应该可以更快上手,第2节我们会介绍怎么准备一个Clojure运行环境
Reading Clojure Characters Clojure本身有很多语法糖,各种符号对于初学者来说容易造成困扰,此文是关于各种语法糖的一个总结
2.Jepsen运行环境搭建
要运行Jepsen测试首先要有java和Clojure运行环境,通过安装lein(Clojure集成开发工具),可以把它们都准备好。我们可以参考Jepsen代码中的DockerFile制作一个docker image,该image包含运行Jepsen测试程序需要的所有环境依赖,同时将jepsen源代码copy到/jepsen目录。通过该docker image我们可以直接在测试机上启动容器,在容器里面运行Jepsen测试。
进入容器执行如下命令
#启动容器 sudo docker run -ti -d --hostname=jepsen_control --name=jepsen_control docker_image /usr/sbin/init #进入容器 docker exec -ti jepsen_control bash #进入demo代码 cd /jepsen/jepsen.etcdemo #启动Clojure解释器 lein repl通过Clojure解释器,可以运行一些示例代码,帮助学习Clojure语言。
2.3 运行Jepsen测试
2.3.1 启动控制节点和DB节点容器
运行Jepsen测试,我们需要至少启动两个docker容器,一个作为控制节点,另一个作为DB节点。
#启动控制节点 sudo docker run -ti -d --hostname=jepsen_control --name=jepsen_control docker_image /usr/sbin/init #启动一个DB节点 sudo docker run -ti -d --hostname=n1 --name=n1 docker_image /usr/sbin/init -
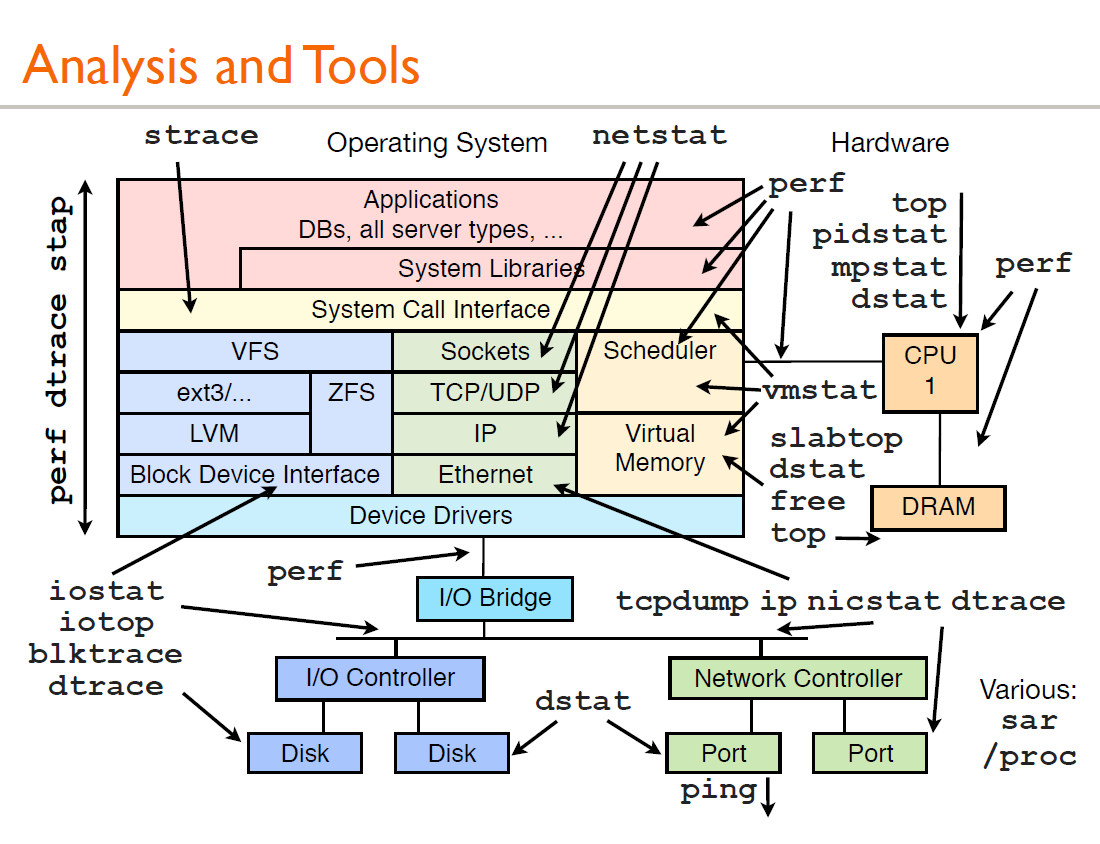
性能优化工具:perf
2020年12月19日 阅读(1,920)主页:https://perf.wiki.kernel.org/index.php/Main_Page
使用:http://www.brendangregg.com/perf.html 系统级性能分析工具perf的介绍与使用
源码:https://github.com/torvalds/linux/tree/master/tools/perf/
- statistics/count: increment an integer counter on events
- sample: collect details (eg, instruction pointer or stack) from a subset of events (once every …)
- trace: collect details from every event

对事件进行:
计数(stat);实时分析(top);
采样(record);文本分析(script);内置分析(report);汇编级分析(annotate)
自定义事件(probe)
1.性能profile
perf record进行采样,结果存入当前目录下的perf.data文件,二进制格式
perf script得到文本形式
perf report对perf.data进行分析,产生分析报告
perf diff可以对perf.data.old和perf.data的两个文件数据进行比较,找到每个函数的差异点
perf record -a --call-graph dwarf -p 29052 perf report --call-graph perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
火焰图生成源码:
https://github.com/brendangregg/FlameGraph
火焰图:
https://cacm.acm.org/magazines/2016/6/202665-the-flame-graph/fulltext
https://nicedoc.io/brendangregg/FlameGraph
1.1 record
记录事件采样数据到文件中。包含如下信息:
comm, tid, pid, time, cpu, event, trace, ip, sym, dso, addr, symoff, srcline, period
1.2 report
可以根据不同的维度进行聚合:–sort可以指定聚合的维度
可以根据不同的条件进行过滤:-c –pid= –tid=
report输出解读:
https://zh-blog.logan.tw/2019/10/06/intro-to-perf-events-and-call-graph/
https://www.man7.org/linux/man-pages/man1/perf-report.1.html
The overhead can be shown in two columns as Children and Self when perf collects callchains. The self overhead is simply calculated by adding all period values of the entry - usually a function (symbol). This is the value that perf shows traditionally and sum of all the self overhead values should be 100%. The children overhead is calculated by adding all period values of the child functions so that it can show the total overhead of the higher level functions even if they don’t directly execute much. Children here means functions that are called from another (parent) function.
-
-
性能优化
2020年12月19日 阅读(855)Optimized C++:Proven Techniques for Heightened Performance
Structure Member Alignment, Padding and Data Packing
1.通用优化规则
a.静态分析工具:clang
wiki:http://clang.llvm.org/extra/index.html
check list:https://clang.llvm.org/extra/clang-tidy/checks/list.html
性能优化相关:
https://clang.llvm.org/extra/clang-tidy/checks/performance-faster-string-find.html
https://clang.llvm.org/extra/clang-tidy/checks/performance-inefficient-string-concatenation.html
https://clang.llvm.org/extra/clang-tidy/checks/performance-inefficient-vector-operation.html
https://clang.llvm.org/extra/clang-tidy/checks/performance-unnecessary-copy-initialization.html
https://clang.llvm.org/extra/clang-tidy/checks/performance-unnecessary-value-param.html
b.grep
1)字符串:拼接 a = a + b => a +=b , find("c") => find('c') 2)分支预测:PANGU_LIKELY PANGU_UNLIKELY 3)vector reserve & proto repeated Reserve 4)loop内条件避免函数调用:for (size_t i = 0; i < size(); ++i) 5)it++ => ++it 6)短函数 => inline #原则经常访问的函数进行inline,不经常访问的代码做成函数,减少cache miss 7)stl map set:[]与find冗余,重复查找 8)内存对齐 struct定义变量顺序,按照大小顺序进行定义 9)乘除浮点运算 => + - 位运算 大规则 1)减少内存分配和copy: 参数传引用,避免大对象的copy,常用的临时性对象不用new用内存池,避免在不同线程分配释放内存 2)优化算法&数据结构:map->unordered_map,去stl容器 3)锁的scope要尽量小,无锁,TLS存储,协程 4)使用更高效的lib库实现:tcmalloc
-
linux问题调查工具指南
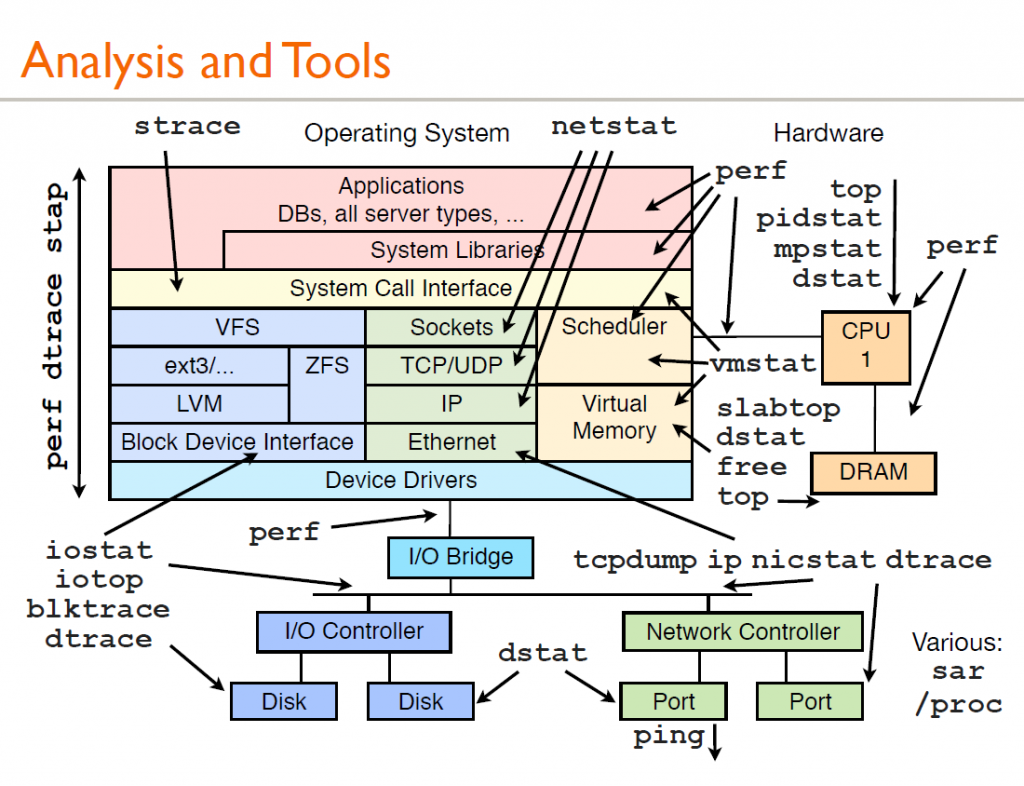
2020年10月1日 阅读(860)1.工具概览
图源:http://www.brendangregg.com/linuxperf.html
2.网络
一个网络包的旅程:https://102.alibaba.com/detail/?id=166
2.1 网络连通性
#检查网络连通性(通过ping网关/对端网关/对端进行分段测试,通过tcpdump确认是否收到包) netstat -rn #查看网关,以0.0.0.0开始的行的gateway是默认网关 ping 127.0.0.1 -s 64000 #指定packet size进行ping,一般应小于1ms sudo tcpdump -i eth2 icmp #抓ping的包 #检查网卡状态 ip addr show #state是否是UP ip link set eth0 up #启用被禁用的网卡 ip route show ifconfig route -n #查看路由表 ip route get 127.0.0.1 //返回目标ip最终实际所选用的路由 #检查iptables配置 sudo iptables --list-rules #检查tc配置 sudo tc qdisc show dev eth2 #telent检查端口连通性 telnet 127.0.0.1 2376
-
深度探索分布式理论经典论文
2019年8月3日 阅读(3,804)1.序
通过对Google发表的论文进行梳理,我们了解到了当前分布式系统领域的一些最新热点和发展趋势。梳理下这些论文,我们会发现它们主要发表在OSDI、SOSP、SIGMOD、VLDB、Macro、Eurosys、SIGCOMM、CIDR、SIGARCH、SIGCOMM等顶级期刊和会议上。反过来通过关注这些会议和期刊,我们就可以持续跟踪该领域的最新进展。但是也会发现这些会议和期刊每个每年都会发表几十上百篇文章,让人应接不暇。同时如在第一篇文章所指出的,这些文章背后的理论基础却很少发生变化,基本上还是几十年前就已提出的。为了更好更快地理解这些层出不穷的新论文,理清其所依赖的理论基础显得尤为重要。正如前文所述,”如果要真正理解这些论文,除了论文本身内容之外,也还需要去了解传统的分布式系统和关系数据库理论”。
-
Google论文、开源与云计算
2019年8月3日 阅读(3,344)1.Google论文与开源
自1998年成立,至今Google已走过20个年头。在这20年里,Google不断地发表一些对于自己来说已经过时甚至不再使用的技术的论文,但是发表之后总会有类似系统被业界实现出来,也足以说明google的技术至少领先业界数年。在Amazon不断引领全球云计算浪潮开发出一系列面向普罗大众的云产品的同时;Google也在不断引领构建着满足互联网时代海量数据的存储计算和查询分析需求的软硬件基础设施。
-
A Study of Linux File System Evolution(笔记)
2018年11月24日 阅读(1,321)原文:https://www.usenix.org/system/files/login/articles/03_lu_010-017_final.pdf
本文对Linux从2003(Linux2.6.0)到2011(linux2.6.39)的八年时间里,各个文件系统(XFS, ext4, Btrfs, ext3, ReiserFS, JFS)提交的总共5079个patch进行了整理分析,得出了一些有趣的观察和结论:
-
-
-
-
-
-
Solution of a Problem in Concurrent Programming Control(译)
2018年9月27日 阅读(2,356)作者:Edsger W. Dijkstra 1965
原文:https://www.di.ens.fr/~pouzet/cours/systeme/bib/dijkstra.pdf
译者:phylips@bmy 2018-9-27
相互之间可以通过有限方式进行通信的一组独立的sequential-cyclic进程,可以通过某种方式使得在任意时刻它们只有一个进入它们自己的“critical-section”。
-
163 blog留念
2018年9月16日 阅读(846)1.留念
网易163 blog要停止服务了,看到这个消息颇感遗憾。截图以留念
08-18十年,460篇文章,150多万访问量,估计写了上百万字。其中的内容可以借黄庭坚的诗句总结一下: 桃李春风一杯酒,酒中真意; 江湖夜雨十年灯,灯下苦读。2.新的开始
目前已经把163上的日志都迁移到了我的个人站点,欢迎大家访问:duanple.com
3.关于本人
网名phylips@bmy,源于很多年前在兵马俑bbs的网名,关于这段历史的更多描述可以查看这篇文章:我的读书历程–暨bmy往事追忆。
-
线性一致性理论
2018年6月30日 阅读(4,651)图片无法查看,可以访问这个链接阅读:https://zhuanlan.zhihu.com/p/338057286
Jepsen(项目主页)是开源的分布式测试框架,基于Clojure语言,支持各种错误注入。目前广泛应用在各种分布式系统的测试中,尤其是一致性协议实现的测试中。Jepsen测试中支持验证系统的线性一致性,关于线性一致性,中文的介绍非常少,目前网上能搜到的大概只有tidb(一个创业公司PingCAP研发的分布式数据库)的一篇Linearizability 一致性验证。
要理解理论,最好的方法还是直接去看建立这个理论的原始论文,于是在业余时间对相关论文进行了阅读。其中第1)篇我做了一个完整的翻译,其他几篇由于篇幅和时间的原因仅进行了阅读。本文下面的内容主要源自阅读如下4篇论文后的理解,如果你觉得还有不好理解的地方欢迎指出,想深入了解一下的也可以再看下原文。首先简单介绍下每篇论文涉及的内容: -
How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs(译)
2018年6月30日 阅读(1,399)作者:Leslie Lamport 1979
原文:
make-multiprocessor-computer-correctly-executes-multiprocess-programs
译者:phylips@bmy 2018-03-24
译文:http://duanple.blog.163.com/blog/static/70971767201822515346732/
高速处理器可能乱序执行程序。如果处理器满足如下条件就可以保证执行的正确性:执行的结果与按照程序描述的顺序执行的结果一致。满足该条件的处理器我们就认为是sequential的。假设一台计算机由共享内存的多个这样的处理器组成。在设计和证明运行在该计算机上的多进程算法[1]-[3]的正确性时,通常基于如下假设:执行结果与这些处理器以某一串行顺序执行的结果相同,同时每个处理器内部操作的执行看起来又与程序描述的顺序一致。满足该条件的多处理器系统我们就认为是sequential consistent的。每个处理器内部满足sequential并不保证多处理器系统是sequential consistent的。在本文中,我们描述了一种sequential处理器(具有内存模块)之间的互联方法,可以保证最终的多处理器系统是sequential consistent的。
-
WordPress使用总结
2018年6月29日 阅读(1,249)欢迎使用WordPress。这是系统自动生成的演示文章。编辑或者删除它,然后开始您的博客!
1.wordprocess 插件安装需要ftp解决方法
wp-config.php,添加以下代码
define(“FS_METHOD”,”direct”);
define(“FS_CHMOD_DIR”, 0777);
define(“FS_CHMOD_FILE”, 0777);
搞定.这时又会提醒无法安装,理由是文件无法创建目录,这个好解决.给wordpress添加权限就好